setwd("C:/Desktop/DSR/Session 2")Exercise 2 : Industrial disputes and parliamentary left seat shares, 1960-2010
Session 2
Download datasets on your computer
Put them a subfolder called data in your working directory.
Load data
First, set your working directory:
Then, use the readxl::read_excel function to load the dataset.
repository <- "data"library(readxl)
# load data
cws <- readxl::read_excel(paste0(repository, "/CWS-data-2020.xlsx"))Explore the dataset
Solution
nrow(cws)[1] 1299
Solution
str(cws)tibble [1,299 × 400] (S3: tbl_df/tbl/data.frame)
$ id : chr [1:1299] "AUL" "AUL" "AUL" "AUL" ...
$ idn : num [1:1299] 1 1 1 1 1 1 1 1 1 1 ...
$ year : num [1:1299] 1960 1961 1962 1963 1964 ...
$ lisrpr_tot : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisrpr_child : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisrpr_eld : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisrpr_tpf : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisrpr_smf : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pct_csmf : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pre_tot : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pre_singm : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pre_eld : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pre_ue : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ post_ue : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pregini_2559 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ postgini_2559 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pregini_1864 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ postgini_1864 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisgini : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisd9010 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisd9050 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ lisd8020 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ mktmeasure : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ postginioecd : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ preginioecd : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ ginimkt_1865 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ ginidisp_1865 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p9010de : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p8020de : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ mgini : num [1:1299] NA NA NA NA NA NA NA 40.6 40.6 40.6 ...
$ ngini : num [1:1299] NA NA NA NA NA NA NA 28.5 28.4 28.4 ...
$ rred : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ abred : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ top1 : num [1:1299] 0.0669 0.0671 0.0682 0.0697 0.0648 0.0634 0.0616 0.0625 0.0605 0.0592 ...
$ top10 : num [1:1299] 0.279 0.281 0.285 0.287 0.279 ...
$ mid : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ bottom : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ top1share : num [1:1299] 7.09 7.1 7.23 7.36 6.84 6.69 6.47 6.58 6.38 6.25 ...
$ top1sharec : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ top1tenshare : num [1:1299] 1.62 1.65 1.64 1.65 1.52 1.46 1.41 1.51 1.4 1.42 ...
$ top1tensharec : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ miwsenc : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ compens : num [1:1299] 8391 8661 9179 10038 11271 ...
$ earnprod : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ wages : num [1:1299] NA NA 4.48 4.66 4.95 ...
$ lowpay : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p90p50 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p50p10 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p90p50v2 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p50p10v2 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ p90p10 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ sstaxes : num [1:1299] NA NA NA NA NA 0 0 0 0 0 ...
$ pytaxes : num [1:1299] NA NA NA NA NA 0.6 0.6 0.6 0.6 0.6 ...
$ topmtax3 : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ gen : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ uegen : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ sickgen : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pengen : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ usucavg : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ ssscavg : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ unempsi : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ unempco : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ sstran : num [1:1299] 3.85 4.28 4.1 4.1 3.91 ...
$ hlpub : num [1:1299] 327 353 392 411 456 ...
$ totheal : num [1:1299] 650 726 745 815 923 ...
$ ptotheal : num [1:1299] 50.3 48.7 52.6 50.4 49.4 ...
$ phealgdp : num [1:1299] 1.84 1.97 2.02 1.92 1.95 ...
$ pcrexnc : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ tcrexnc : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ pinpat : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ tinpat : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ poupat : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ toupat : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ tmedcv : num [1:1299] NA 76 76 78 80 82 83 84 83 83 ...
$ pmedcv : num [1:1299] NA 76 76 78 80 82 83 84 83 83 ...
$ inpatcv : num [1:1299] 77 79 80 80 81 84 86 88 86 87 ...
$ outpatcv : num [1:1299] NA 76 76 78 80 82 83 84 83 83 ...
$ daycare : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ oldage_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ survivor_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ incap_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ health_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ family_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ almp_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ unemp_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ housing_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ other_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ socx_pub : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ oldage_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ survivor_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ incap_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ health_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ family_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ almp_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ unemp_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ housing_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ other_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ socx_pmp : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
$ almppes : num [1:1299] NA NA NA NA NA NA NA NA NA NA ...
[list output truncated]
Solution
View(cws)
Clue
The syntax is the following:
dataset %>% select(var1, var2, var3) %>% function1 %>% function2
Solution
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unioncws %>% select(id, year, nld, leftseat) %>% str()tibble [1,299 × 4] (S3: tbl_df/tbl/data.frame)
$ id : chr [1:1299] "AUL" "AUL" "AUL" "AUL" ...
$ year : num [1:1299] 1960 1961 1962 1963 1964 ...
$ nld : num [1:1299] 1145 815 1183 1250 1334 ...
$ leftseat: num [1:1299] 36.9 37.9 49.2 48.5 41 41 40.3 33.1 33.1 35.5 ...
Clue
See ?table in the help.
Solution
cws %>% select(id) %>% table()id
AUL AUS BEL CAN DEN FIN FRA FRG GRE IRE ITA JPN LUX NET NOR NZL POR SPA SWE SWZ
59 59 59 59 59 59 59 59 59 59 59 59 59 59 59 60 59 59 59 59
UKM USA
59 59 or
table(cws$id)
AUL AUS BEL CAN DEN FIN FRA FRG GRE IRE ITA JPN LUX NET NOR NZL POR SPA SWE SWZ
59 59 59 59 59 59 59 59 59 59 59 59 59 59 59 60 59 59 59 59
UKM USA
59 59
Clue
See ?summary in the help
Solution
summary(cws$leftseat) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.0 30.7 40.2 37.2 47.8 70.3 62
Clue
The syntax is the following using the dplyr package. var_sum is not a name of a function but the future name of your aggregated variable var.
dataset %>%
group_by(year) %>%
summarise(
var_sum = sum(var, na.rm = TRUE)
)
Solution
cws %>%
group_by(year) %>%
summarise(
nld_sum = sum(nld, na.rm = TRUE)
)# A tibble: 60 × 2
year nld_sum
<dbl> <dbl>
1 1960 13080
2 1961 14385
3 1962 14704
4 1963 15021
5 1964 15620
6 1965 14951
7 1966 14140
8 1967 14440
9 1968 15101
10 1969 19874
# ℹ 50 more rows
Solution
dataset <- cws %>%
group_by(year) %>%
summarise(
nld = mean(nld, na.rm = TRUE),
leftseat = mean(leftseat, na.rm = TRUE)
)
head(dataset)# A tibble: 6 × 3
year nld leftseat
<dbl> <dbl> <dbl>
1 1960 769. 33.4
2 1961 899. 33.2
3 1962 919 33.1
4 1963 939. 33.7
5 1964 976. 33.8
6 1965 934. 34.2
Clue
Use the ggplot2 functions geom_point, geom_smooth and geom_text.
Solution
library(ggplot2)
p <- ggplot(dataset) +
geom_point(aes(x = year, y = nld), color="red", size = 1) +
geom_smooth(aes(x = year, y = nld), method = "lm") +
geom_text(aes(x = year, y = nld, label = year),
angle = 45, size = 3)p`geom_smooth()` using formula = 'y ~ x'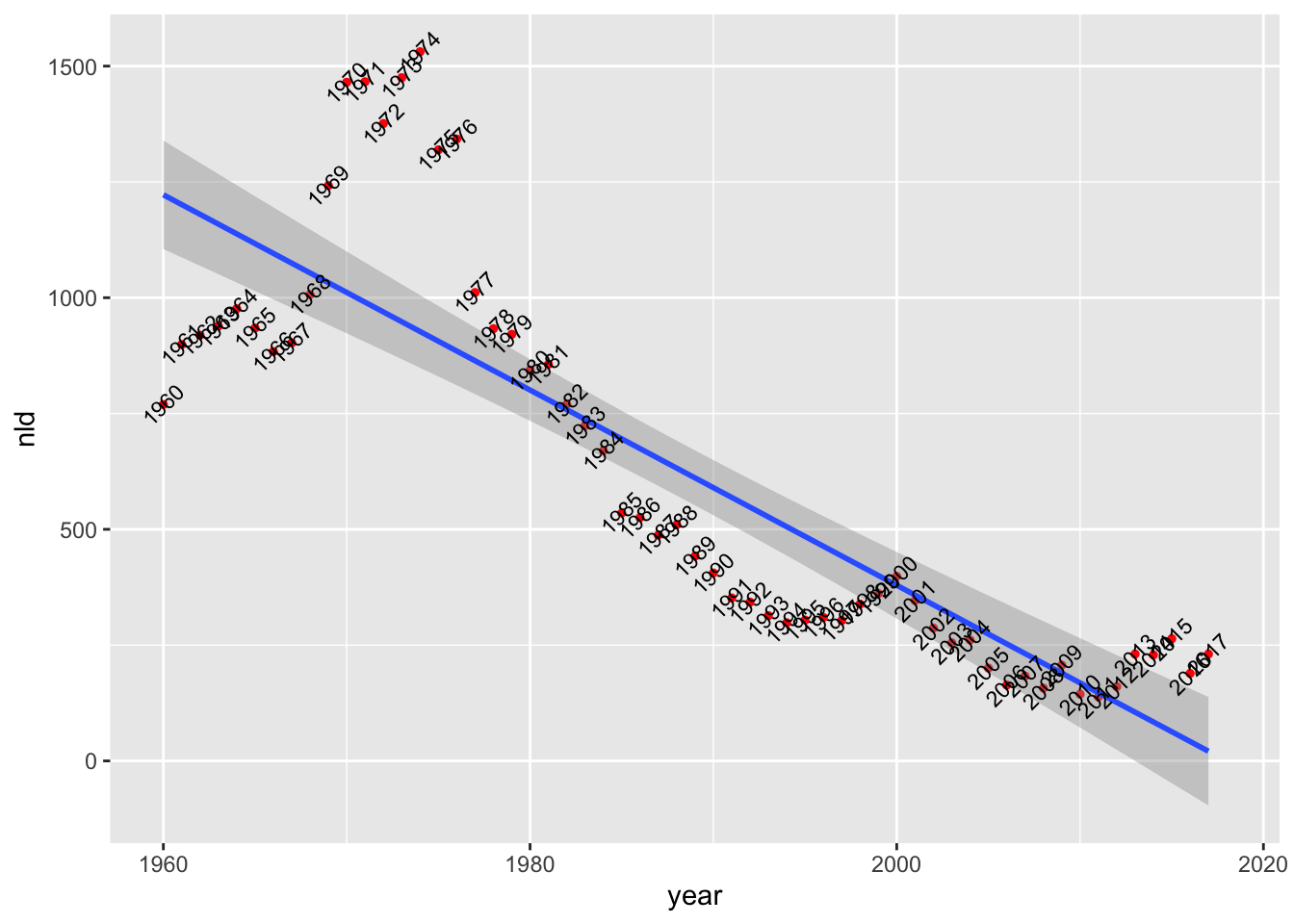
Source
Data sources
Comparative Welfare States (CWS) dataset, 2020 https://www.lisdatacenter.org/news-and-events/comparative-welfare-states-dataset-2020/