[1] -0.01879769 0.29734468 -0.72161879 0.81348481 -0.58172615 -0.05933099
[7] 0.32264855 0.54180014 1.63311884 1.80059136 25% 50% 75%
-0.7437115 0.1055856 0.7417393 [1] 0.1055856Session 6
2024-03-12
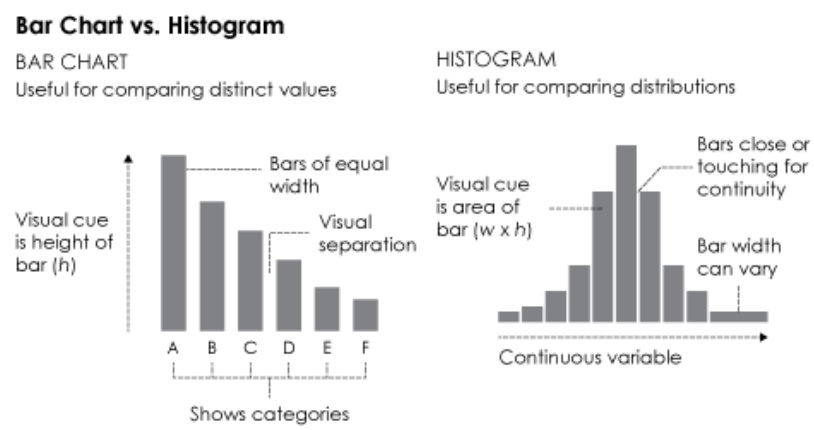
There are many visual representations of distributions using plots.
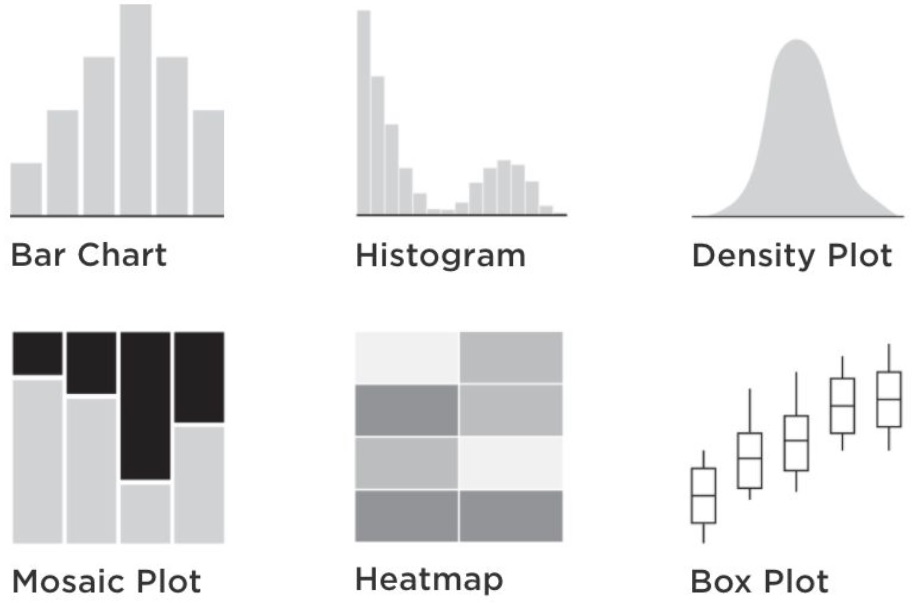
Histograms: A graphical representation of the frequency distribution of data. It divides the data into intervals (bins) and displays the number of data points in each bin. Histograms help understand the shape and spread of data.
Density Curves: A smoothed representation of the distribution of data. It provides insights into the probability density function of continuous data. Density curves are often used to approximate the shape of distributions.