Data 2
Session 4
2024-02-27
Exercise 1
The article “Measuring Public Support for European Integration across Time and Countries: The ‘European Mood’ Indicator” by Isabelle Guinaudeau and Tinette Schnatterer addresses the challenge of measuring public support for the European Union (EU), in the context of increasing contestation of European integration. They emphasize the need for a consistent and comparable instrument to measure citizens’ preferences and to analyze the dynamic relationship between public opinion, party politics, and policy making.
Exercise 2
In this article, Hermann Schmitt, Sara B. Hobolt, and Wouter van der Brug describe the results of a post-election study, conducted in all 28 EU member states after the elections to the European Parliament were held between 23 and 26 May 2019. The main objective of the 2019 EES Voter study is to study electoral participation and voting behaviour in European Parliament elections.
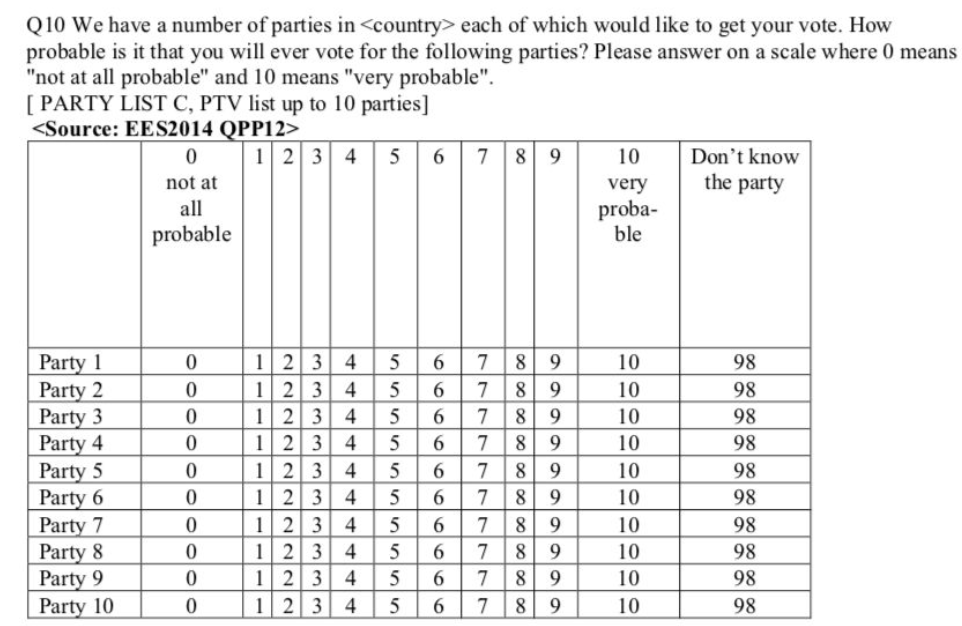
In particular, question 10 ask how probable is it that people will ever vote for different parties in their country.
Reshaping (pivoting)
Reshaping involves restructuring data to transform it from a wide format to a long format or vice versa.

Splitting (separating)
Splitting involves breaking a dataset into smaller groups based on a specified variable, allowing for separate analysis and manipulation of each group’s data.

Merging (joining)
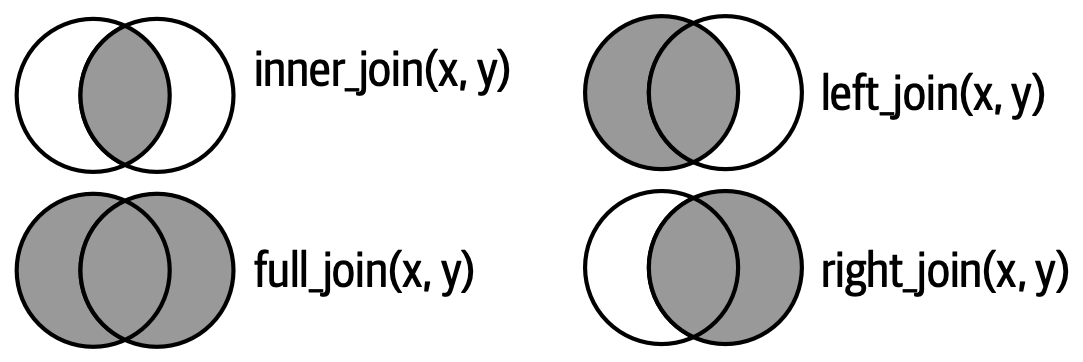
Merging involves combining multiple datasets based on shared variables to create a single unified dataset:
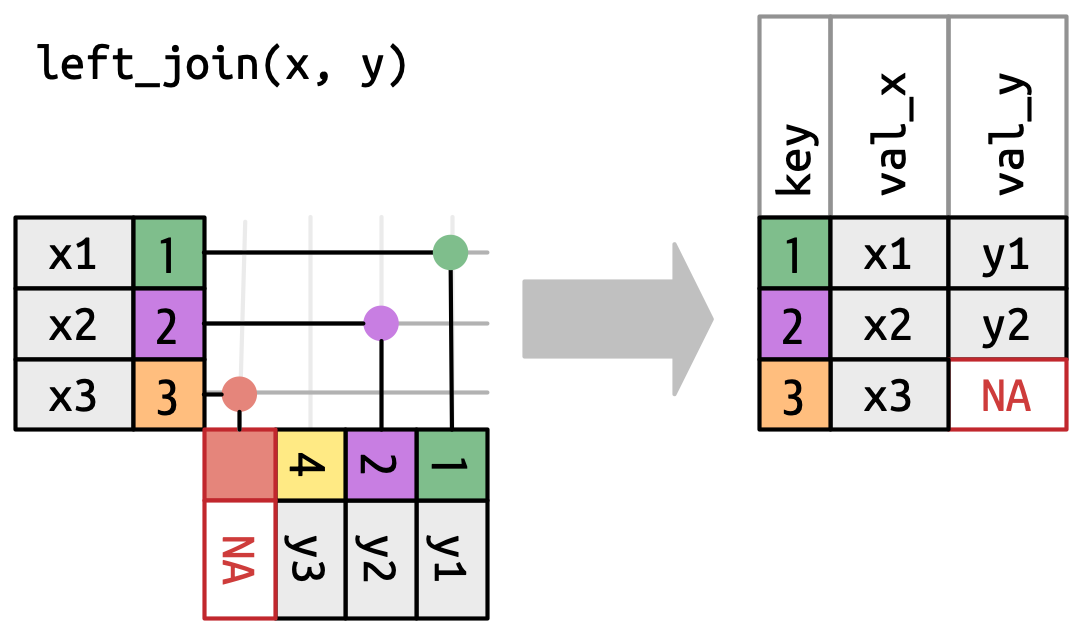
- Left Join: Includes all records from the left dataset and matching records from the right dataset.
- Right Join: Includes all records from the right dataset and matching records from the left dataset.
- Inner Join: Includes only matching records from both datasets.
- Full Join: Includes all records from both datasets, filling in with NA where there are no matches.
More Cheatsheets