4 Data 2
Session 4
By the end of this session, you have learned more on dplyr tools.
In a nutshell
- Utilizing more
dplyrfunctions for data manipulation- merging datasets
- wide and long formats
- string detection
- …
- [Bonus] Understanding databases, including dbplyr for connections.
4.1 Continue to wrangle
4.1.1 Exercises
Exercise 1
The article “Measuring Public Support for European Integration across Time and Countries: The ‘European Mood’ Indicator” by Isabelle Guinaudeau and Tinette Schnatterer addresses the challenge of measuring public support for the European Union (EU), in the context of increasing contestation of European integration. They emphasize the need for a consistent and comparable instrument to measure citizens’ preferences and to analyze the dynamic relationship between public opinion, party politics, and policy making.
Exercise 2
In this article, Hermann Schmitt, Sara B. Hobolt, and Wouter van der Brug describe the results of a post-election study, conducted in all 28 EU member states after the elections to the European Parliament were held between 23 and 26 May 2019. The main objective of the 2019 EES Voter study is to study electoral participation and voting behaviour in European Parliament elections.
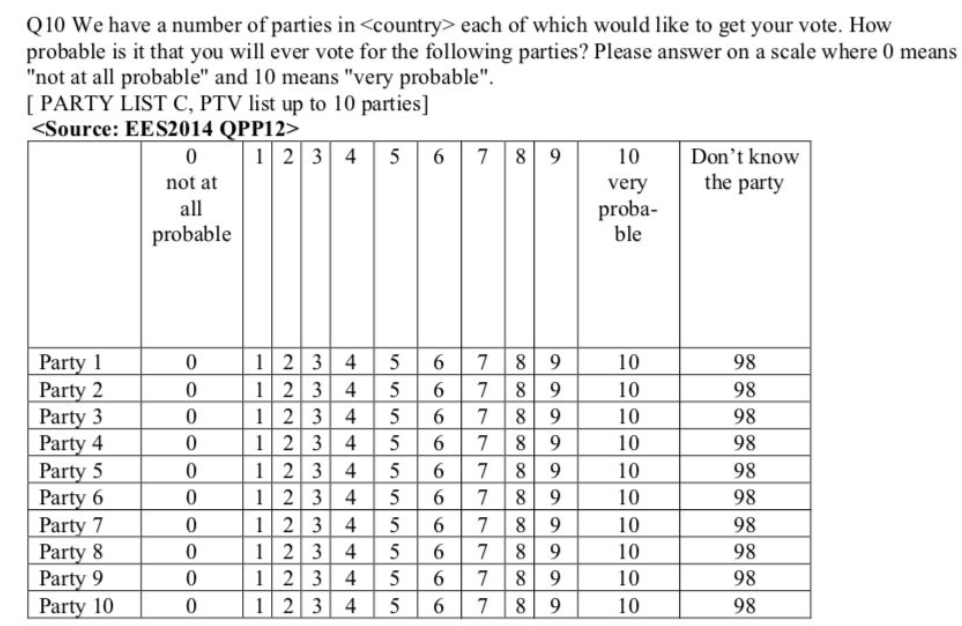
In particular, question 10 ask how probable is it that people will ever vote for different parties in their country.
4.1.2 More on Tidying data
Reshaping (pivoting)
Reshaping involves restructuring data to transform it from a wide format to a long format or vice versa.

Splitting (separating)
Splitting involves breaking a dataset into smaller groups based on a specified variable, allowing for separate analysis and manipulation of each group’s data.

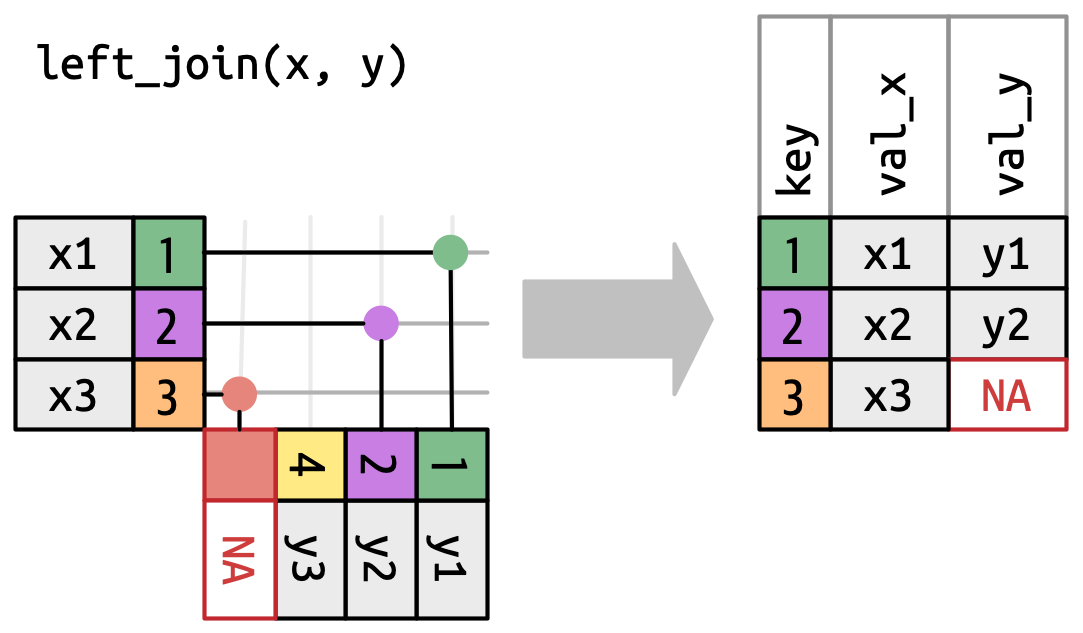
Merging (joining)
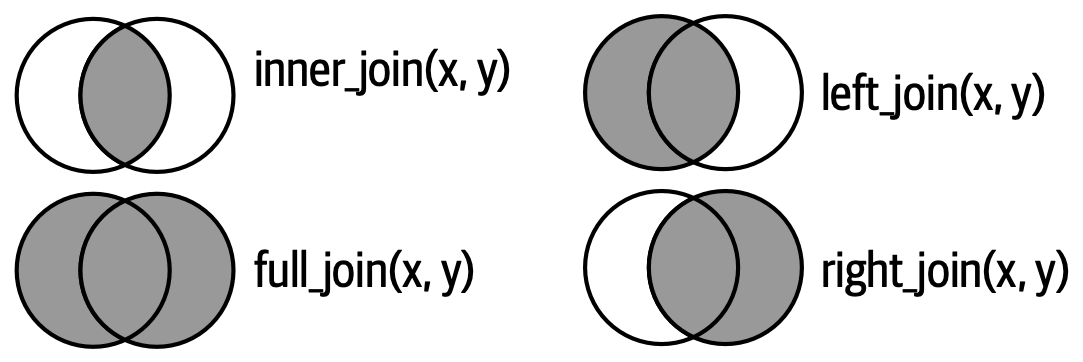
Merging involves combining multiple datasets based on shared variables to create a single unified dataset:
- Left Join: Includes all records from the left dataset and matching records from the right dataset.
- Right Join: Includes all records from the right dataset and matching records from the left dataset.
- Inner Join: Includes only matching records from both datasets.
- Full Join: Includes all records from both datasets, filling in with NA where there are no matches.
4.1.3 More Cheatsheets

Exam 1
- Instructions here
- in group & graded
- real-world dataset (road traffic accidents in France)
- data cleaning and data analysis tasks
- Submit a script called
exam1_solution.R(Subject : “DSR Exam 1 Submission”, To : kim.antunez@sciencespo.fr) - Deadline : mar. 12th, before 7:15 pm.
- Make sure your script is well-organized
Homework for next week
Exercise 2 from today (questions 1 to 7)
1 preparation exercise (in group & ungraded, for now)
- Use the hints
- Search for help online (e.g. StackOverflow, more than ChatGPT)
- be persistent (you will need it) and do your best!
Handbooks, videos, cheatsheets
- 3 chapters (1 Irizarry, 1 Healy, 1 Wickham et al)
- 3 compulsory Cheatsheets
4.2 Bonus : databases
Databases serve as organized repositories of data structured into tables with defined relationships:
- They employ common ‘id’ columns to establish connections between different tables
- Optimised for speed with large data tables/streams
- Requires learning a DB query language
Two main approaches are available for managing data within databases:
- Standard, SQL : predominantly row-oriented and comes in various versions to suit different database systems.
- Alternatively, MonetDB : employs a column-oriented structure
The dbplyr package acts as a connector that extends the capabilities of dplyr. It relies on ODBC/DBI drivers, which enable R to connect and communicate with a diverse array of database management systems:
- MySQL
- PostgreSQL
- SQLite
- Microsoft SQL Server
- Oracle
There are also specialized drivers available for MonetDB such as:
- MonetDB.R
- MonetDBLite
But also :
bigrqueryR package for Google BigQuery, a cloud-based data warehousing solution.- …
You can refer to Chapter 22 (ʻDatabasesʼ) in the book “R for Data Science” by Grolemund and Wickham or here.